
When designing applications, one of the most critical decisions architects and CTOs must make is selecting the right foundational data-layer components. The data-layer serves as the backbone of your application’s performance, scalability, availability, and security, making it a crucial element to get right from the outset.
In this guide, we will explore four powerful open-source technologies that are essential at the data layer:
- Apache Cassandra®
- Apache Kafka®
- Apache Spark™
- OpenSearch®
These technologies, when selected and implemented properly, can significantly enhance your application’s architecture. However, it’s important to understand the challenges and considerations involved when choosing the right technology for your needs.
6 Key Challenges When Making Technology Choices:
- Hiring Challenges:
- Choosing new technologies may require specialized expertise, which can be hard to find. Opting for technologies with large, active communities can make hiring easier, as there is more readily available expertise.
- Quick Response to Business Requirements:
- The right technology choice will allow your team to respond quickly to changing business needs, keeping your organization agile.
- Managing Technical Debt:
- Technical debt can slow down progress and impact employee morale. The best technologies help minimize this debt and make it easier to consolidate solutions over time.
- Security and Compliance:
- Ensure that your chosen technology supports the necessary security and compliance requirements (e.g., GDPR, SOC 2, PCI) to protect sensitive data and meet industry regulations.
- Vendor Management:
- Open-source technologies offer flexibility, helping you avoid vendor lock-in and ensuring that you can make future technology decisions with more freedom.
- Legacy Challenges:
- For organizations with existing legacy systems, adopting new technologies should enable smooth transitions and facilitate digital transformation without disrupting ongoing operations.
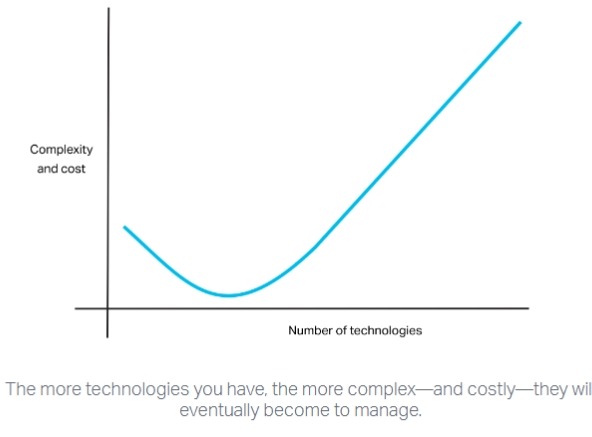
How to Evaluate Technology Solutions:
When evaluating data-layer technologies, it’s important to focus on:
- Business Requirements: Ensure the technology aligns with the long-term goals of the business, not just the immediate needs.
- Complexity: Avoid unnecessary complexity that could increase costs and overhead.
- Interoperability: Consider how the technology will interact with existing systems, both internally and externally.
- Long-Term Viability: Think about scalability and how well the technology will support future growth.
Sometimes, choosing a technology that may seem less cutting-edge could be the best decision in terms of support, ease of integration, and performance.
Understanding Key Data-Layer Technologies:
- Apache Cassandra®:
- Overview: Cassandra is a distributed NoSQL database designed for scalability and high availability. Its leaderless architecture and ability to handle large amounts of data across multiple nodes make it ideal for applications requiring high uptime and performance.
- When to Use:
- When you need a highly available, scalable system.
- When you require cross-data-center replication.
- If your application demands availability of 99.9% or more.
- When NOT to Use:
- For applications requiring pure analytics or data warehousing.
- When you need fast, real-time analytics, as Cassandra isn’t suited for that.
- Apache Kafka®:
- Overview: Kafka is a distributed streaming platform that acts as a message queue for managing real-time data feeds. Kafka is well-suited for high-throughput, low-latency applications, such as data pipelines and real-time event-driven architectures.
- When to Use:
- For handling large volumes of real-time data.
- If you need to manage event streams across microservices.
- To integrate systems that need to communicate asynchronously.
- When NOT to Use:
- For systems that do not require event-driven architecture.
- If your application doesn’t require real-time processing or message streaming.
- Apache Spark™:
- Overview: Spark is a unified analytics engine designed for large-scale data processing. It can handle batch processing, real-time streaming, and interactive queries, making it ideal for big data environments.
- When to Use:
- For large-scale data analytics, including machine learning and data processing pipelines.
- If you need both batch and stream processing.
- When building real-time data processing applications.
- When NOT to Use:
- If you don’t require complex analytics or distributed processing.
- When working with small data sets, as Spark is optimized for large-scale applications.
- OpenSearch®:
- Overview: OpenSearch is an open-source search and analytics suite derived from Elasticsearch. It is used for log analytics, full-text search, and analytics on large datasets.
- When to Use:
- If you need full-text search capabilities for large volumes of data.
- For log aggregation and monitoring.
- When building applications that require search functionality or real-time analytics.
- When NOT to Use:
- For systems that require high-complexity, multi-table joins (OpenSearch is not a relational database).
- When the search layer is not critical to your application.
This article is posted at instaclustr.com

Please fill out the form to access the content





